Redis in Modern Systems
Redis is one of the most influential building blocks in modern system architecture. When used intentionally, it simplifies coordination, scaling, and shared state across services. This article explores how Redis works under the hood and how to design systems that take full advantage of it.

If you built backend systems in the late 2000s or early 2010s, you remember the pain. Databases were the bottleneck. Scaling meant vertical upgrades, buying bigger hardware until you ran out of budget or physics. Every performance problem turned into another index, another replica, or another late night trying to shave milliseconds off complex SQL JOINs.
Then Redis showed up.
For the first time, you could put state in memory, share it across processes, give it a TTL, and move on. APIs got faster. Databases stopped melting. Systems felt forgiving for the first time. That first experience stuck. For many teams, Redis became “the cache”, a tactical fix for performance problems.
Redis, short for REmote DIctionary Server, was originally built as a network-accessible in-memory dictionary, but with a crucial difference. It exposed structured data and deterministic operations rather than opaque blobs. That design choice mattered more than it seemed at the time.
But stopping at “Redis is a cache” is a mistake. Originally released in 2009 by Salvatore Sanfilippo, Redis was designed to answer a specific question: how do you serve data fast enough for real-time applications? Over the last 15 years, that narrow goal evolved into a general-purpose in-memory data structure server.
Today, Redis sits at the core of the modern tech stack. It is the shared memory between stateless microservices. It is the coordination layer for distributed locks. It is the buffer for high-velocity telemetry.
Why Redis Is Fast?
When engineers ask why Redis is fast, the common answer is "it runs in RAM." While true, that is only half the story. If you wrote a naive Java or Python application that stored data in RAM, it would still likely be slower than Redis under high concurrency.
Redis performance is the result of three specific architectural choices:
The Single-Threaded Event Loop
Redis (mostly) uses a single thread to handle commands. This seems counter-intuitive in an era of multi-core CPUs, but it is a feature, not a bug.
By running on a single thread, Redis avoids context switching and race conditions. It never needs to acquire a lock to update a value, because no other thread can touch that value at the same time. This creates predictable tail latency. In multi-threaded systems, performance often degrades non-linearly as threads fight for locks. In Redis, performance is linear until the CPU is saturated.
Note: Modern Redis isn't strictly single-threaded. It uses background threads ("bio" threads) for heavy tasks like closing file descriptors (UNLINK) and flushing data to disk (fsync), keeping the main event loop unblocked.
I/O Multiplexing
How does a single thread handle 50,000 concurrent client connections? Redis uses I/O multiplexing (typically epoll on Linux or kqueue on macOS/BSD).
Instead of blocking the thread waiting for a client to send data, Redis asks the kernel to monitor all open socket connections. When a socket becomes readable, the kernel wakes up the Redis thread, which processes the command, writes the response to a buffer, and moves instantly to the next socket.
Memory Efficiency and Specialized Encodings
Redis is obsessive about memory layout. It doesn't just store standard linked lists or hash tables. It adapts the underlying data structure based on the size of the data to optimize for CPU cache locality.
- Ziplists / Listpacks: If you store a small list or hash, Redis stores it as a contiguous block of memory (a byte array) rather than a structure with pointers. This reduces memory fragmentation.
- IntSets: If a Set contains only integers, Redis stores them as a sorted array of integers. This uses a fraction of the memory required for a standard hash table.
From Cache to Control Plane: The Use Cases
Most teams adopt Redis in stages as system complexity increases. What begins as simple caching often grows into session storage and analytics, and eventually becomes a coordination layer for distributed systems.
Phase 1: Read Optimization (Caching)
This is where everyone starts. The application checks Redis; if the data is missing, it queries the database and populates Redis.
- Value: Reduced latency and reduced database load.
- Risk: Cache invalidation. If the database changes and Redis isn't updated, users see stale data. The hardest part of caching is not storing data, but knowing when to delete it.
Phase 2: Transient State (Sessions & Analytics)
Here, Redis is the primary store for data that can be lost without catastrophe.
- Session Storage: User sessions are read on every request. Storing them in a database is overkill; storing them in a stateless JWT works but makes revocation hard. Redis is the middle ground: fast reads with instant revocation.
- HyperLogLog: For analytics, you can use probabilistic structures. A HyperLogLog allows you to count unique items (like daily active users) with an error rate of <1% using only 12KB of memory, regardless of how many users you have.
Phase 3: Distributed Coordination (The Control Plane)
This is where Redis becomes critical infrastructure. In a microservices architecture, you need a way for services to agree on the state of the world.
Distributed Locks
If you have five worker processes processing payments, how do you ensure a specific order isn't processed twice? You use a Redis lock.
Using SET resource_name my_random_value NX PX 30000, you can acquire a lock that auto-expires in 30 seconds.
The critical part is releasing the lock safely. You cannot just DEL the key, because you might delete a lock held by another process if yours took too long. You must use a Lua script to check ownership and delete atomically:
-- Release lock only if ownership matches
if redis.call("get", KEYS[1]) == ARGV[1] then
return redis.call("del", KEYS[1])
else
return 0
end
Rate Limiting
API Gateways often rely on Redis to enforce quotas (e.g., "100 requests per minute"). Using the INCR command and EXPIRE, a cluster of stateless servers can enforce a global limit without talking to each other directly.
Redis and Microservices
Microservices amplify coordination problems. Once a system is decomposed into many stateless services, shared state does not disappear. It just becomes harder to manage. Rate limits, idempotency, retries, leader election, and job ownership all become cross-cutting concerns that no single service naturally owns.
Redis fits microservices not because it is fast, but because it provides a shared, low-latency coordination layer without forcing services to share databases or schemas. In microservice architectures, Redis commonly owns coordination invariants, not domain data. Earlier use cases like rate limiting and idempotency become architectural glue rather than isolated features.
From a design standpoint, Redis reduces the need for "coordination microservices" whose sole responsibility is managing shared state. Entire services can disappear when their responsibilities collapse into Redis primitives. The trade-off is blast radius. Redis becomes part of the system’s control plane. If Redis is slow or unavailable, many services feel it at once.
That means Redis usage in microservices must be intentional. Invariants owned by Redis should be explicit, documented, and tested. Lua scripts should be versioned like application code. Failure modes should be designed, not discovered in production.
Persistence: RDB vs. AOF
One of the biggest shocks for new Redis administrators is discovering that Redis can lose data. Understanding persistence is mandatory for production environments.
RDB (Redis Database Snapshot)
RDB creates a point-in-time snapshot of your dataset at specified intervals (e.g., "every 5 minutes if 100 keys changed").
- Pros: Compact binary files, fast startup time.
- Cons: If Redis crashes, you lose all data written since the last snapshot.
- The "Fork" Danger: To create a snapshot, Redis calls the fork() syscall. The OS uses Copy-on-Write (CoW) to clone the process memory. If your dataset is huge (e.g., 40GB) and you have heavy write traffic during the snapshot, your memory usage can double, potentially causing the OS to OOM-kill Redis.
AOF (Append Only File)
AOF logs every write operation received by the server. When Redis restarts, it replays the log to reconstruct the dataset.
- Pros: Much higher durability. You can configure fsync to run every second.
- Cons: The file grows indefinitely (though Redis rewrites it in the background) and recovery is slower than RDB.
Recommendation: For pure caching, disable both (or use RDB for warm restarts). For a general-purpose store, use RDB + AOF with fsync set to everysec.
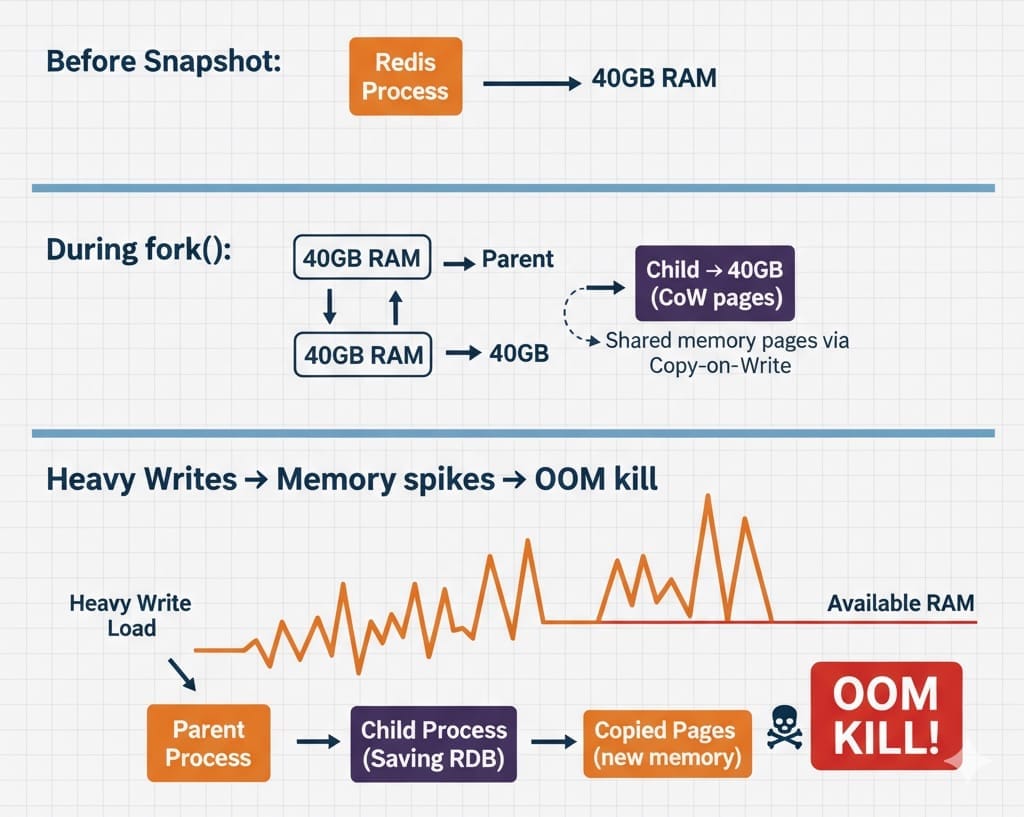
fork() under write-heavy loadScaling Redis
When a single Redis node runs out of memory or CPU, you have two paths.
Path A: High Availability with Redis Sentinel
Sentinel is a system designed to keep Redis online. It monitors a primary node and its replicas. If the primary dies, Sentinel coordinates an election and promotes a replica to primary.
- Architecture: 1 Primary + N Replicas.
Limitation: You are limited by the RAM of a single node. You cannot store 200GB of data if your server only has 64GB. Writes are also limited to the throughput of one node.
Path B: Horizontal Scaling with Redis Cluster
Redis Cluster shards data across multiple nodes. It splits the keyspace into 16,384 "hash slots." Every key belongs to a slot, and every slot belongs to a node.
- Architecture: N Primaries + N Replicas.
- Pros: You can scale to Terabytes of RAM.
Cons: Complexity. Client libraries must be "cluster-aware." Multi-key operations (like transactions or MGET) are only allowed if all keys involved hash to the same slot. This requires careful data modeling using "hash tags" (e.g., {user:100}:profile and {user:100}:orders ensure both keys land on the same shard).
The Ecosystem Fracture: Redis vs. Valkey
In 2024, Redis Ltd. transitioned the project from the permissive BSD license to the RSAL/SSPL license. This restricted cloud providers from selling managed Redis services without paying. In response, the Linux Foundation, backed by AWS, Google, and Oracle, forked the last open version of Redis to create Valkey.
What does this mean for you?
Functionally, Valkey 7.x/8.x and Redis 7.x are nearly identical for the end user. The commands, protocols, and data structures remain the same. However, for new deployments, many engineering teams and Linux distributions are defaulting to Valkey to ensure long-term open-source compatibility.
Production Anti-Patterns and Failure Modes
There are some common, repeatable failure modes seen when you use Redis beyond simple caching and become part of the system’s coordination layer.
Latency Killers: Blocking the Event Loop
The KEYS Command
KEYS pattern* is an O(N) operation. On a dataset with millions of keys, Redis scans everything. Because Redis executes commands on a single thread, the entire server stops responding until the scan finishes.
This is not a slow query problem. It is a full stop.
- Fix: Rename or disable
KEYSinredis.conf. UseSCAN, which is incremental and non-blocking.
The Big Key
Storing massive hashes, lists, or sets creates latency cliffs. Deleting a 500MB collection forces Redis to free memory element by element, blocking the event loop.
- Fix: Use
UNLINKinstead ofDELfor non-blocking deletes. Model data so collections remain bounded.
Availability Killers: Self-Inflicted Outages
Connection Storms
When application fleets restart, thousands of clients may reconnect simultaneously. TLS handshakes and authentication can drive Redis CPU to 100 percent, causing connection timeouts, retries, and cascading failure.
- Fix: Use connection pooling, jittered reconnects, and exponential backoff.
Scalability Killers: Load That Does Not Distribute
The Hot Key
In a healthy cluster, traffic spreads evenly. In a hot key scenario, a single key (for example, global_feature_flags) receives the majority of traffic. One shard saturates while others sit idle. The system appears overloaded despite unused capacity.
Redis Cluster cannot solve this automatically.
- Fix: Redesign key structure, introduce client-side caching, or split the key into multiple buckets.
Correctness Killers: When Performance Settings Delete Data
Maxmemory Policy Misconfiguration
What happens when Redis runs out of RAM depends entirely on maxmemory-policy.
noeviction: Writes fail once memory is exhausted.allkeys-lru: Any key can be evicted, including coordination state.
The trap appears when Redis is used for both caching and durable queues. An eviction policy intended for cache keys can silently delete queue items or locks.
- Fix: Use
volatile-lruand ensure only cache keys have TTLs. Never allow eviction to apply to coordination state.
Closing Thoughts
Redis is easy to adopt but hard to master. Teams that use Redis only as a cache benefit from speed. Teams that understand it as a distributed data structure server gain architectural leverage. They can build queues, real-time analytics, and coordination systems without adding new infrastructure complexity.
The difference is not in the commands you type, but in understanding the consequences of those commands on the single-threaded engine underneath. Treat Redis with the same respect you treat your primary database, and it will be the most reliable part of your stack.