Synchronized Expiration in Distributed Systems
Caching is not about speed. It’s about load control. Deterministic TTL creates hidden synchronization points that eventually break under scale. This deep dive explains how mature systems design for expiration, not just performance.

It’s 12:05 PM. Your user traffic is perfectly flat. Database CPU is stable at 38%. Suddenly, within seconds, CPU spikes to 100%. Connection pools max out. Query latency jumps from 40ms to over 3 seconds. Timeouts trigger retries. Retries amplify load. Amplified load creates more timeouts.
By 12:07 PM, your database is effectively dead.
When you dig into the logs, you don’t find a DDoS attack or a viral marketing push. You find something much more ordinary and much more dangerous. At 12:00 PM, a cron job ran, or perhaps a massive influx of users logged in for a scheduled event. Their data was cached with a standard 5-minute Time-To-Live (TTL). Now, at 12:05 PM, thousands of cache keys have expired at the exact same millisecond. Your application servers, finding the cache empty, all rush to the database simultaneously to fetch the same data.
This is Synchronized Expiration, often leading to the "Thundering Herd" problem. In a distributed system, relying on simple, fixed TTLs is a ticking time bomb.
When the cache is healthy, it absorbs and smooths demand. When many keys expire together, regeneration load is released in a concentrated burst instead of being spread over time. The failure sequence looks like this:
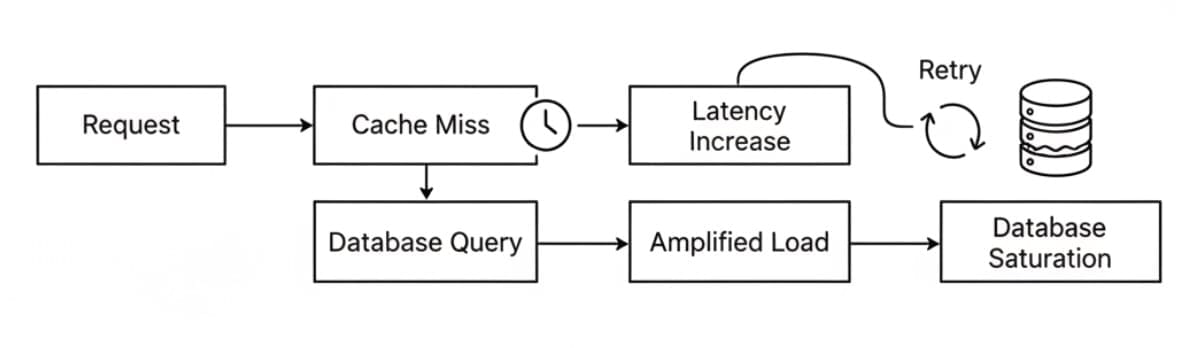
Most large-scale outages are triggered by synchronized events rather than gradual overload.
Why TTL is a Time Bomb in Distributed Systems
In low-traffic systems, TTL behaves exactly as expected. Data expires, the next request fetches fresh data, and the system continues normally.
In highly concurrent distributed systems, TTL creates hidden synchronization points.
When a hot object is first requested, hundreds of application servers cache it at roughly the same moment. If the TTL is 300 seconds, those servers will independently decide the data is stale at roughly the same moment 300 seconds later.
Real-world traffic follows a power-law distribution. A tiny percentage of hot keys absorb the majority of reads. Applications like Instagram experience this constantly. When a global celebrity like Cristiano Ronaldo or Taylor Swift posts, tens of millions of users open the app to view the same profile, follower count, and engagement metrics. Those profile objects become extremely hot keys.
If those keys expire simultaneously, millions of requests instantly bypass cache protection and converge on backend databases. The database is not sized for total traffic. It is sized for cache misses. When misses spike beyond expected levels, collapse is immediate.
Autoscaling also does not solve this. Scaling decisions operate on seconds-to-minutes timescales. Cache stampedes occur in milliseconds.
To survive scale, expiration must be treated as a probabilistic and distributed process, not a fixed boundary.
1. TTL Jitter
The simplest and highest-leverage fix is to introduce randomness into expiration.
Instead of assigning:
TTL = 300 seconds
You assign:
TTL = 300 seconds + random(-30, +30)
This converts expiration from a synchronized event into a distributed one. The same amount of regeneration work occurs, but it is spread over time instead of concentrated into a single spike.

The trade-off is bounded inconsistency. Some users may see data slightly longer than others. In exchange, peak database load drops dramatically. This is almost always worth it.
2. Request Coalescing
Jitter reduces alignment but does not eliminate regeneration pressure for extremely hot keys. Request coalescing ensures only one worker regenerates the cache while others wait or use stale data.
Using Redis:
SET lock:key worker_id NX PX 5000If successful, that worker queries the database and updates the cache. Other workers defer. Only one worker regenerates the value; other workers do not query the database.
However, distributed locking introduces its own failure modes. If a worker pauses due to garbage collection or network delay, the lock may expire prematurely. Another worker acquires the lock and performs the same regeneration. The original worker resumes and overwrites the cache with stale data.
Production-grade systems mitigate this using fencing tokens or monotonic version numbers. Each regeneration receives a strictly increasing version. Only newer versions are allowed to update the cache.
3. Stale-While-Revalidate
Traditional caching blocks on expiration:
Cache Miss → Database Query → Response
Stale-While-Revalidate changes the model:
Cache Expired → Serve Stale Data → Refresh in Background
Consider a Cricket World Cup final. Virat Kohli is batting. Tens of millions of users refresh simultaneously to check his score. If the cache on player key expires, blocking all requests on regeneration would overwhelm the database. Instead, the system can server the slightly stale data immediately and asynchronously refreshes the cache.
This isn't just a backend application pattern. Modern CDNs (like Cloudflare and Fastly) and reverse proxies (like Nginx and Varnish) support this natively via the Cache-Control: stale-while-revalidate HTTP header.
X applies similar logic to celebrity follower counts. When millions of users open a celebrity profile, the follower count may be a few seconds behind reality. The system prioritizes availability over perfect real-time accuracy.
4. Probabilistic Early Refresh
Standard TTL creates a step function: Fresh → Expired.
Probabilistic refresh can convert this into a ramp. The closer a key gets to expiration, the higher the probability a request triggers a background refresh.
if cache_age > threshold:
probability = (cache_age - threshold) / (TTL - threshold)
if random() < probability:
async_refresh()
This ensures popular keys are refreshed before expiration. Regeneration happens gradually and invisibly, instead of synchronously and catastrophically.
You don't always have to write this math from scratch. Modern local caching libraries, like Java’s Caffeine, have features like refreshAfterWrite built-in, which automatically handles probabilistic early refresh and coalescing for L1 caches without requiring custom locking code.
5. Cache Warming
Cache warming proactively refreshes hot keys before users request them. There are two approaches:
Mathematical approach: Track access frequency using probabilistic structures like Count-Min Sketch to identify hot keys dynamically.
Domain-driven approach: Use business knowledge. In cricket or fantasy platforms, tomorrow’s match schedule is known in advance. Player profiles, statistics, and leaderboards can be preloaded overnight when database load is low. Similarly, Instagram/X know which accounts have hundreds of millions of followers. Their profiles are continuously refreshed in cache regardless of access patterns.
This shifts regeneration work to off-peak periods when database contention is lower.
The Eviction Trap: Cache warming is dangerous if you lack memory headroom. If you aggressively warm tomorrow's data, you might trigger an Out of Memory (OOM) event or an LRU eviction policy that deletes today's hot keys. Always align your bulk warming scripts with your distributed cache memory limits.
6. Multi-Layer Caching: Reducing Blast Radius
Mature systems use layered caching:
- Layer 1: Local in-process cache (Caffeine, in-memory LRU)
- Layer 2: Distributed cache (Redis, Memcached)
- Layer 3: Database
The L1 cache acts as a localized shock absorber. If Redis expires, regeneration load is limited to the number of application nodes, not total user requests.
For example: 1 million requests per second hitting 100 nodes becomes 100 regeneration events, not 1 million.
Observability during Cache Stampede
A cache stampede often looks exactly like a database bottleneck if you don't have the right metrics. To detect synchronized expiration before it causes an outage, you must monitor:
- Spiky Cache Miss Rates: If your miss rate is usually flat but occasionally spikes in perfect vertical lines, your TTLs are aligned.
- p99 Database Latency vs. Cache Miss Correlation: If your 99th percentile DB latency perfectly overlaps with cache miss spikes, your cache is acting as a trigger, not a shield.
- Redis CPU vs. Network I/O: If Redis CPU spikes but network throughput drops, you might be experiencing extreme lock contention from poorly implemented coalescing.
The Takeaway
Caching plays a central role in controlling database load. Deterministic TTL creates hidden synchronization points that eventually collapse under load. Production systems distribute regeneration work across time:
- Jitter distributes regeneration.
- Coalescing limits concurrency.
- Stale-while-revalidate protects availability.
- Probabilistic refresh eliminates hard boundaries.
- Cache warming prevents peak regeneration entirely.
- Multi-layer caching reduces blast radius.
- Observability detects the stampede before it happens.
Final Thought:
At scale, synchronized expiration produces failure patterns similar to traffic floods. Treating expiration as a hard boundary concentrates regeneration into short intervals. Add jitter. Use background refresh. Ensure regeneration remains controlled under concentrated access.